Tam: “I just realize that I know nothing about the internet!”
Eric: “Oh, me neither. I just take advantage of it.”
The Internet
The internet is just a bunch of computers talking to each other. Some computers have information stored on them to share with others, we call them servers. Most computers, yours and mine included, just want to acquire information, we call them clients. The clients are the one initiating a conversation; they reach out to the servers requesting information. The servers keep their ears out for requests and response to them.
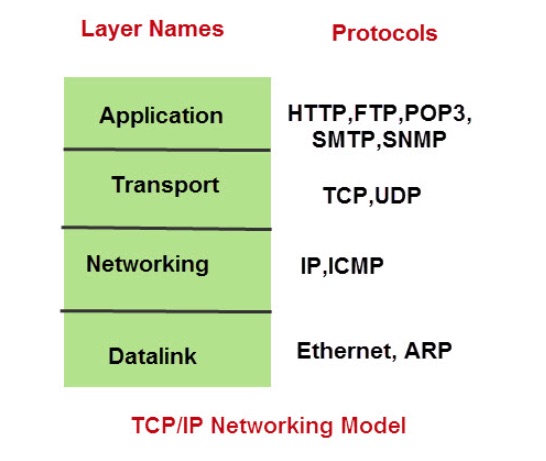
In order to communicate with each other, computers have to follow the same protocols. A protocol suite is a collection of protocols that are designed to work together. Pretty much everything on the web runs on the TCP/IP suite, which is named after the Transmission Control Protocol (TCP) and the Internet Protocol (IP).
TCP is a connection oriented protocol and is used to provides a reliable end to end connection. It has built in error checking and will re-transmit missing packets. IP is the main networking protocol. These two are not the only two protocols in the suite, but they are the most common ones.
Here comes the socket
Computers on TCP/IP network communicate through sockets. A socket is one endpoint of a two-way communication channel, just like a phone is one end of a phone call between two parties. A socket consists of an IP address and a port number. The IP address identifies the device while the port number identifies the application running on that device. Continuing with the phone analogy, if IP address is like a company’s phone number, the port number is like a department’s extension.
An useful IP address to know is 127.0.0.1 or ::1. That is your computer’s localhost.
Port number ranges from 0 to 65535. However, ports 0 through 1023 are reserved for operating system’s use.
Hypertext Transfer Protocol (HTTP)
HTTP is one of many methods of communication on the web. Others include SMTP, FTP, etc… but HTTP is arguably the most popular. Let’s say we want to google something. The communication goes like this:
- Client makes TCP connection to server at www.google.com:80
- Server at www.google.com:80 accepts the connection
- Client sends over the HTTP request over a socket connection specifying what it wants
- Server receives request, parse that request, figure out what it’s asking for, fetch that data (or generate it dynamically), send it back
- Client receives and parses response
- Server closes connection
HTTP is stateless. Once a request is fulfilled, the server doesn’t keep track of anything. In order for to be understood, HTTP requests and responses have to follow certain formats.
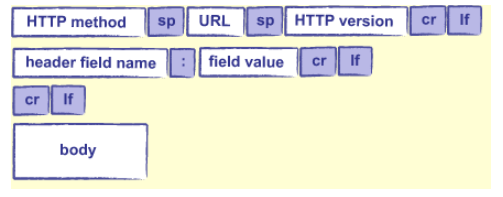
Anatomy of an http request
Anatomy of an http response
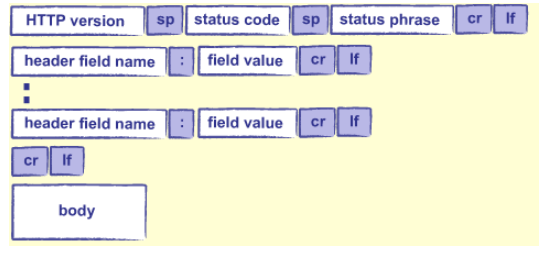
On the request, the HTTP method is almost always either “GET” (to fetch information) or “POST” (to submit form data or upload files). On the response, the status code is a number indicating what happened when the request was processed: 200 means “everything worked”, 404 means “not found”, and other codes have other meanings. The status phrase repeats that information in a human-readable phrase like “OK” or “not found”.
On both the request and the response, http headers allow the client and the server to pass along addition information. They look like key-value pairs; however, one key can sometimes have multiple values. Here is a long list of headers.
Finally, the body includes any extra data associated with the request or response. Data sent back and forth between the server and the client is always a stream of bytes. To tell the receiver what these bytes represent (text, image, or audio, etc…) the sender specifies the media type of the source in the content-type header.